eXo Community Outage: Post Mortem and What You Can Learn
What happened…
In the early morning of Friday, January 17th 2014, we experienced an outage of three services: eXo Community, eXo Blog and eXo Documentation. The services were fully restored at 2:00 pm PST on Friday. Unplanned downtime of any length is unacceptable to us. In this case we fell short of both eXo Tribe’s expectations and our own.
For 12 hours, we worked flat out to restore full access as soon as possible. Though we have shared some brief updates along the way, we owe you a detailed explanation of what happened and what we’ve learned.
Page Load Times
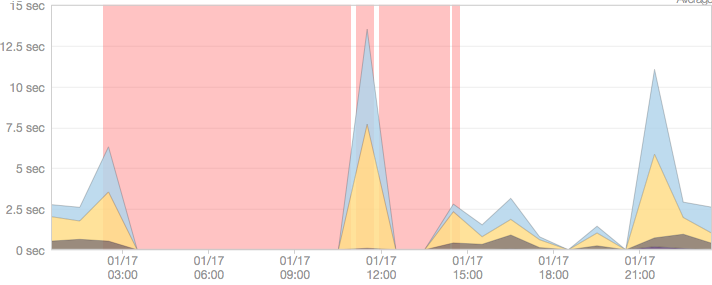
Downtime Event
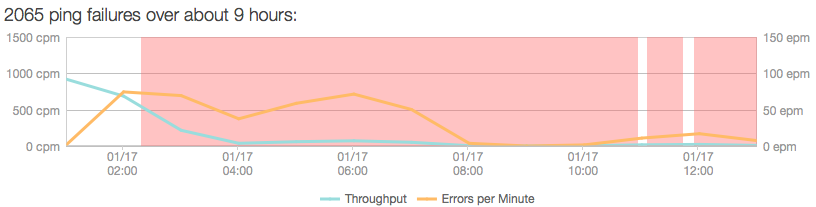
At 2 am, Friday January 17th 2014, the server hosting our three services, eXo Community, eXo Blog and eXo Documentation, crashed. We immediately detected the problem and tried to reset the server. Nevertheless, it could not be started. After quickly considering the server incident, we decided to migrate its storage to a new server. After three hours we succeeded in restoring two services: eXo Blog and eXo Documentation. Unfortunately, despite our best efforts, the crash had damaged eXo Community data.
To restore service as fast as possible, we performed recovery from our latest backups. We were able to restore most functionality within 2.5 hours, but during the data restoration we detected that the hard disk driver where the Community database was stored was erroneous. Its write and read speed was very slow. A quick disk check was launched and detected some bad sectors on the hard disk. We immediately replaced the broken hard disk with a new one and re-launched the data restoration. The above problem slowed the recovery process, and it took until 2 pm PST Friday for eXo Community service to fully return.
And what we’re doing about it…
Regularly check states of whole servers
Over the past few months our infrastructure has grown rapidly to support thousands of users. We routinely upgrade and repurpose our server. We have also been using several monitoring tools to supervise and monitor the states of servers. Nevertheless, we did not perform regular deep system diagnostics. Also, a quick system check should be launched before a data restoration in order to ensure that the whole system returns in a healthy state. These points will always be kept in our mind after this incident.
Faster disaster recovery
When running infrastructure at large scale, the standard practice of running multiple replicas provides redundancy. However, should those replicas fail, the only option is to restore from the latest backup. The standard tool used to recover MySQL data from backups is slow when dealing with large data sets.
To speed up our recovery, we are going to write a tool that parallelizes the replay of binary logs. This enables much faster recovery from large MySQL backups.
We know that you rely on eXo Community to get things done, and we’re very sorry for the disruption. We wanted to share these technical details to shed some light on what we’re doing in response.
Thanks for your patience and support.
Also, feel free to ping the team on the eXo Community website if you wish to know more.